Getting Started¶
These docs are under construction.
Note
If you’re using JupyterLab, “Contextual Help” is supported, and will certainly assist you with general use of the Blueprint Workshop. You can drag the tab to be side-by-side with your notebook to provide instant documentation on the focus of your text cursor.
Initialization¶
Before continuing further, ensure you have initialized the workshop.
Note: The command will fail unless you have correctly followed the instructions in Configuration.
Before any Python examples will work properly, the Workshop must
be initialized.
from datarobot_bp_workshop import Workshop
w = Workshop()
All following examples will assume you have initialized the workshop as above.
Understanding blueprints¶
It’s important to understand what a “blueprint” is within DataRobot. A blueprint represents the high-level end-to-end procedure for fitting the model, including any preprocessing steps, algorithms, and post-processing.
In the Blueprint Workshop, blueprints are represented with a BlueprintGraph,
which can be created by constructing a DAG via Tasks. We’ll drill into the
details later, but this is an example of a BlueprintGraph.
pni = w.Tasks.PNI2(w.TaskInputs.NUM)
rdt = w.Tasks.RDT5(pni)
binning = w.Tasks.BINNING(pni)
keras = w.Tasks.KERASC(rdt, binning)
keras_blueprint = w.BlueprintGraph(keras, name='A blueprint I made with the Python API')
You can save a created blueprint for later use, in either the Blueprint Workshop, or the DataRobot UI.
keras_blueprint.save()
And you can also visualize the blueprint
keras_blueprint.show()

In the UI, blueprints are represented graphically with nodes and edges. Both may be selected and will provide contextual buttons for performing actions on nodes and edges such as removing, modifying, or adding them.
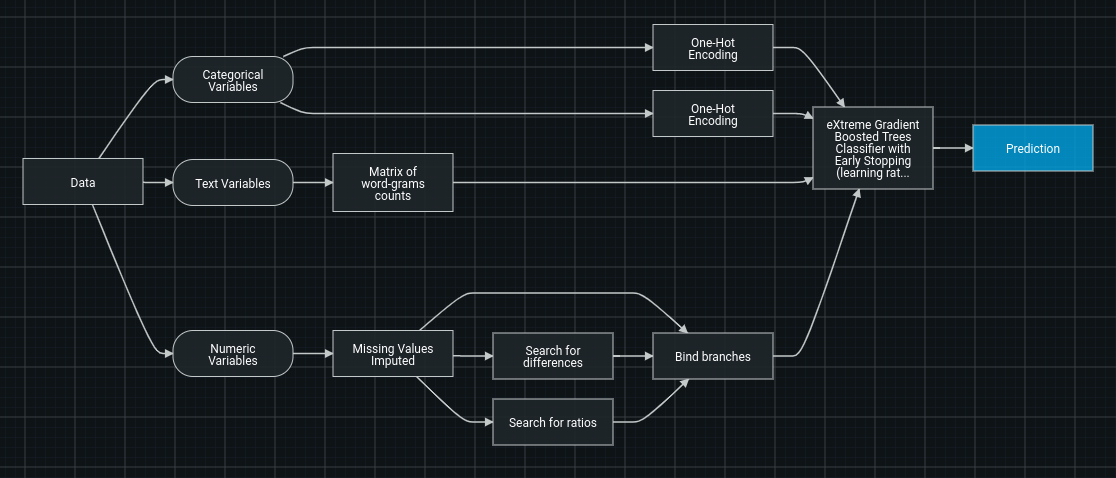
Each blueprint has a few key sections:
The incoming data (“Data”), separated into type (categorical, numeric, text, image, geospatial, etc.).
The tasks performing transformations to the data, for example, “Missing Values Imputed.”.
The model(s) making predictions or possibly supplying stacked predictions to a subsequent model. Post-processing steps, such as “Calibration.”
The data being sent as the final predictions, (“Prediction”).
Each blueprint has nodes and edges (i.e. connections).
A node will take in data, perform an operation, and output the data in its new form. An edge is a representation of the flow of data.
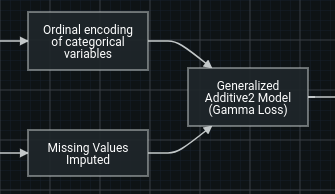
This is a representation of two edges that are received by a single node; the two sets will be stacked horizontally. The column count of the incoming data will be the sum of the two sets of columns, and the row count will remain the same.
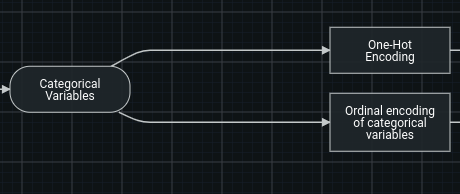
If two edges are output by a single node, it means that the two copies of the output data being sent to other nodes.
Understanding tasks¶
The types of tasks available in DataRobot¶
- DataRobot supports two types of tasks:
Estimator predicts a new value (or values) (y) by using the input data (X). A final task in any blueprint must be an estimator. Examples of estimator tasks are “LogisticRegression”, “LightGBM regressor”, and “Calibrate”
Transform transforms the input data (X) in some ways. Examples of transforms are One-hot encoding, Matrix n-gram, etc
- Despite differences, there are also similarities between these two types of tasks:
Both estimator and transform have a
fit()method which is used to train them (they learn some characteristics of the data). For example, a binning task requiresfit()to define the bins based on training data, and then applies those bins to all incoming data in the future.Both transform and estimator can be used for data preprocessing inside a blueprint. For example, Auto-Tuned N-Gram is an estimator and the next task gets its predictions as an input.
How tasks work together in a blueprint¶
Data is passed through a blueprint sequentially, task by task, left to right.
- During training:
Once data is passed to an estimator, DataRobot first fits it on the received data, then uses the trained estimator to predict on the same data, then passes the predictions further. To reduce overfit, DataRobot passes stacked predictions when the estimator is not the final step in a blueprint.
Once data is passed to a transform, DataRobot first fits it on the received data, then uses it to transform the training data, and passes the result to the next task.
When the trained blueprint is used to make predictions, data is passed through the same
steps - except fit() is being skipped.
Constructing Blueprints¶
Working with tasks¶
As described above, tasks are core to the process of constructing blueprints. Understanding how to add, remove, and modify them in a blueprint is vital to successfully constructing a blueprint.
Defining tasks to be used in a blueprint in Python requires knowing the task code to
construct it. Fortunately between being able to easily search tasks by name, description, or category,
and leverage autocomplete (type w.Tasks.<tab> where you press the Tab key at <tab>),
it should be a breeze to get up and running.
Once you know the task code, you can simply instantiate it.
binning = w.Tasks.BINNING()
Note
If you will be working with the UI, you will need to start with a blueprint from a project leaderboard, so it is recommended you first read how to modify an existing blueprint, and then return here.
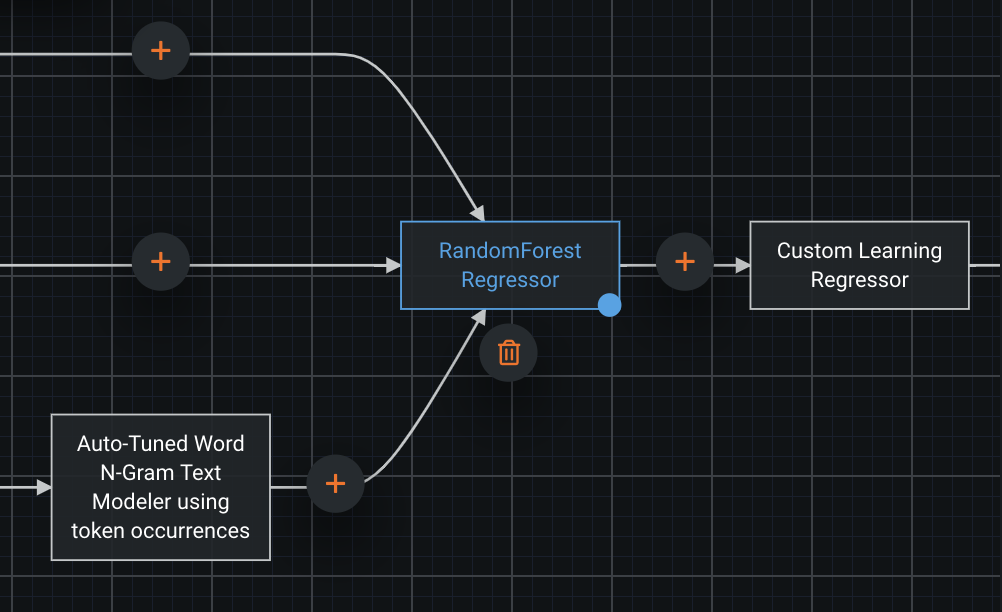
The blueprint editor allows you to add, remove, and modify tasks, their hyperparameters, or their connections.
To modify a task, click a node, then on the associated pencil icon, and edit the task or parameters as desired. Click “Update” when satisfied. (More details)
To add a task, select the node to be its input or output, and click the associated plus sign button. Once the empty node and task dialog appear, choose the task and configure as desired. (More details)
To remove a node, select it and click the associated trash can icon.
Passing data between tasks¶
As mentioned in Understanding blueprints, data is passed from task to task determined by the structure of the blueprint.
Here will are taking numeric input into a task which will perform binning on the numeric input to the blueprint (determined by project and featurelist).
binning = w.Tasks.BINNING(w.TaskInputs.NUM)
Now that we have our binning task defined, passing its output to an estimator is simple.
kerasc = w.Tasks.KERASC(binning)
And now we can save,
visualize or train
what we’ve just created by turning it into a BlueprintGraph.
keras_bp = w.BlueprintGraph(kerasc)
You may pass multiple inputs to a task at construction time, or add more later.
The following code will append to the existing input of kerasc.
impute_missing = w.Tasks.NDC(w.TaskInputs.NUM)
kerasc(impute_missing)
You may replace the input instead, by passing replace_inputs=True.
kerasc(impute_missing, replace_inputs=True)
The BlueprintGraph will reflect these changes, as can be seen by calling .show(),
but to save the changes, you will need to call .save().
keras_bp.save().show()
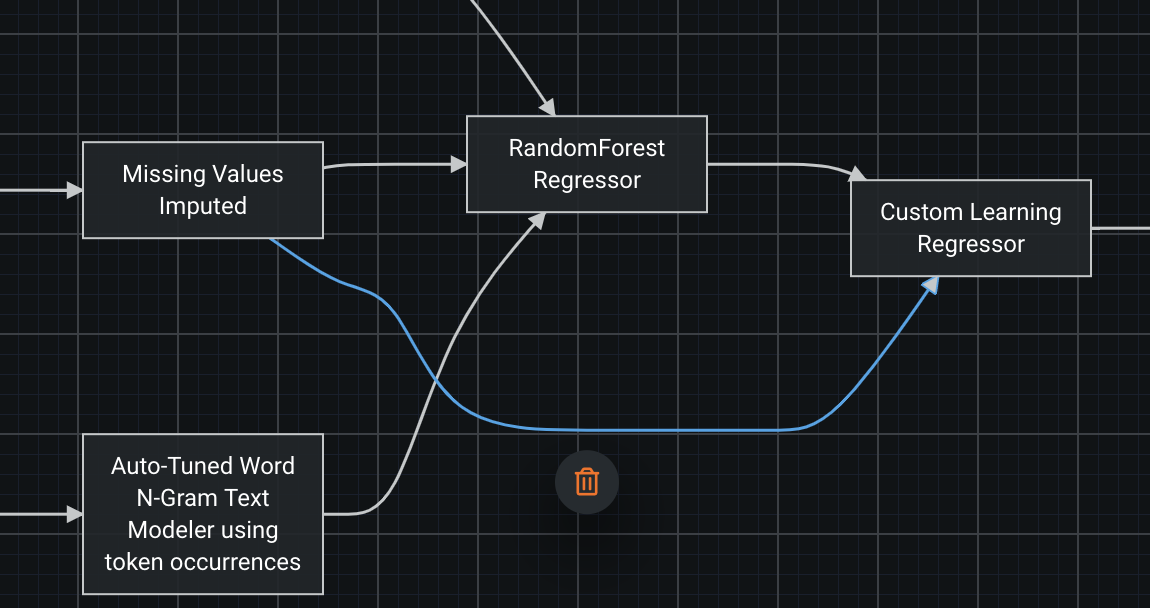
To add a connection, select the starting node and drag the blue knob to the output point.
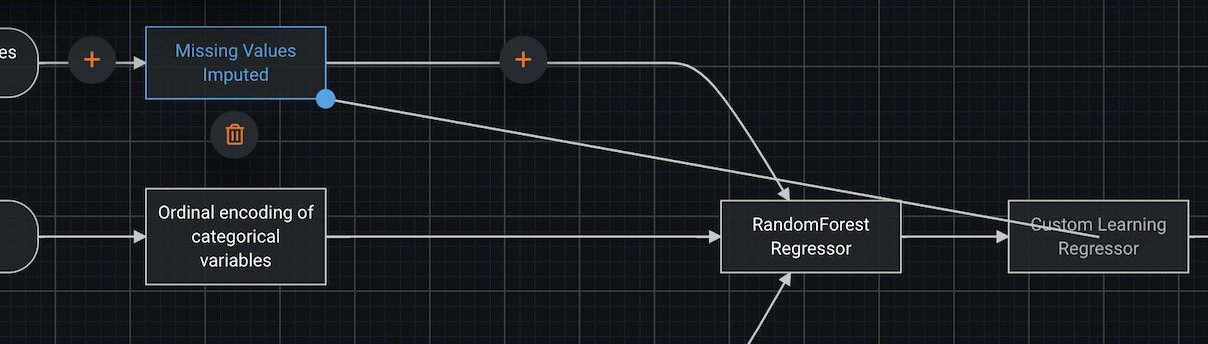
To remove a connection, select the edge which you’d like to remove and click the trash can icon. If the trash can icon does not appear, deleting the connection is not permitted. You must ensure the blueprint is still valid even when you remove the connection you’d like to remove. We have it in our roadmap to allow the blueprint to be in an invalid state.
Modifying an existing task¶
Modifying a task in the context of the Blueprint Workshop means modifying the parameters only, where as in the UI, it can mean modifying the parameters, or which task to use in the focused node as you need to “edit” a task in order to substitute it for another.
Simply use a different task where the substitution is required and save the blueprint.
To modify an existing task, click on the node and then the pencil icon. The Task dialog will appear.
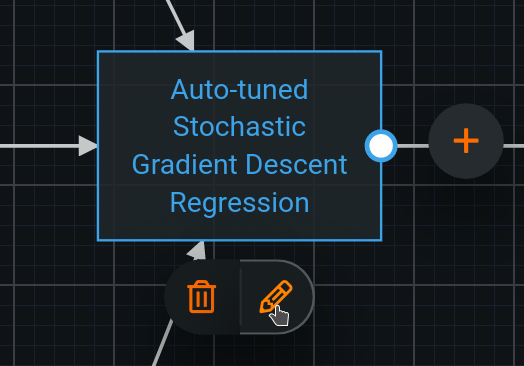
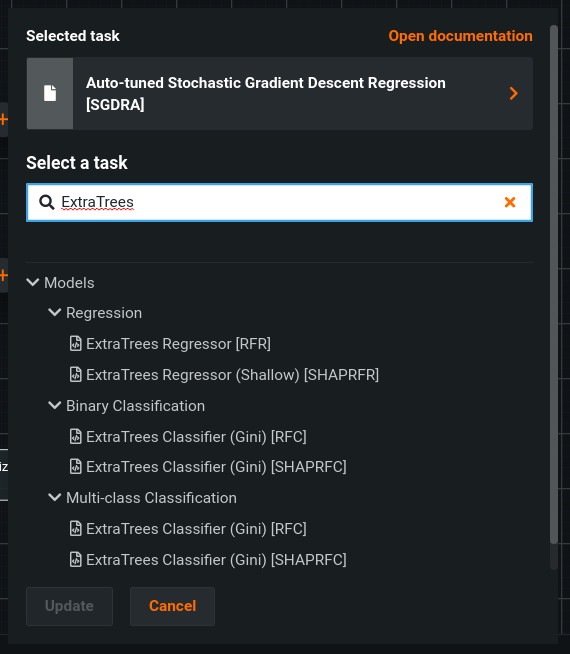
Click on the name of the task for a prompt to choose a new task.

Now you may search and find the specific task you’d like to use. Click Open documentation after selecting a task for details on how the task works
Configuring task parameters¶
Tasks have parameters which can be configured to modify their behavior. This might be things like the learning rate in a stochastic gradient descent algorithm, the loss function in a linear regressor, the number of trees in XGBoost, the max cardinality of a one-hot encoding, and many, many more.
Generally speaking, the following method is the best way to modify the parameters of a
task. It’s also worth noting that it’s a great idea to open the documentation for a
task when working with one. Reminder: If you’re using JupyterLab, “Contextual Help”
is supported, or you may call, e.g. help(w.Tasks.BINNING).
Let’s continue working with our blueprint from above, specifically by modifying the
binning task. Specifically by raising the maximum number of bins and lowering the
the number of samples needed to define a bin.
binning.set_task_parameters_by_name(max_bins=100, minimum_support=10)
There are a number of other ways to work with task parameters, both in terms of retrieving the current values, and modifying them.
It’s worth understanding that each parameter has both a “name” and “key”. The “key” is the source of truth, but it is a highly condensed representation, often one or two characters. So it’s often much easier to work with them by name when possible.
You can modify task parameters as well. Parameters display under the header, and are dependent on the task type.
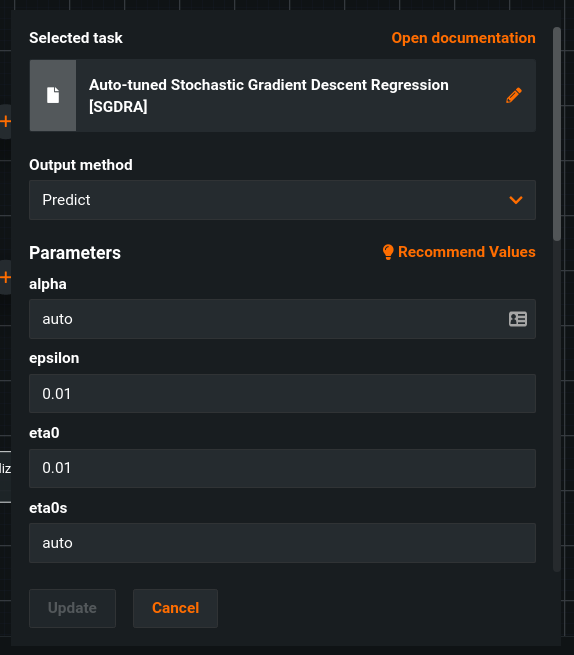
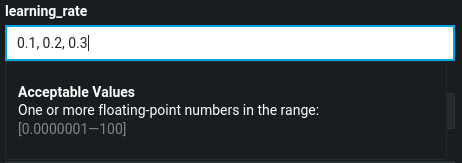
Acceptable values are displayed for each parameter, whether a single value or multiple values in a comma-delimited list.
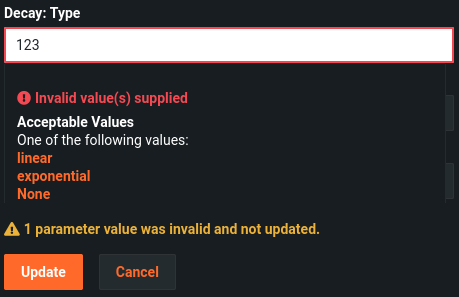
If the selected value is not valid, DataRobot returns an error:
Adding or removing data types¶
A project’s data is organized into a number of different input data types. When constructing a blueprint, these types may be specifically referenced.
When input data of a particular type is passed to a blueprint, only the input types specifically referenced in the blueprint will be used.
Similarly, any input types referenced in the blueprint which do not exist in a project will simply not be executed.
Adding input data types to tasks in the Blueprint Workshop is easy! It’s the same as adding any other input(s) to a task.
For the sake of demonstration, we add numeric input, then subsequently add date input, but could have just as easily added them both at once.
ndc = w.Tasks.NDC(w.TaskInputs.NUM)
ndc(w.TaskInputs.DATE)
If the current blueprint does not have all of the input variable types that you’d like to use, you can add more. It’s as easy as selecting the “Data” node, and clicking the “edit” icon to modify the input data types available to use in the current blueprint.
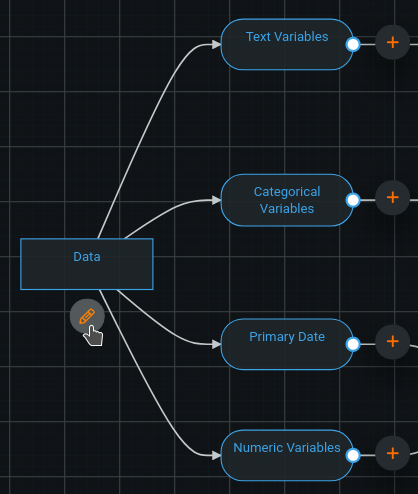
With this modal, you may select any valid input data, even those not currently visible in the blueprint. You can then drag the connection handle in order to denote data passing to the target task.
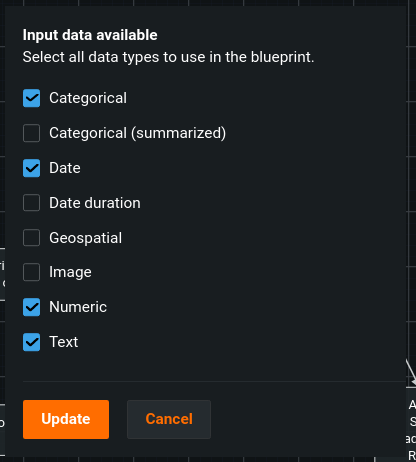
Modifying an existing blueprint¶
Suppose you’ve run Autopilot and have a Leaderboard of models, each with their performance measured. You identify a model that you would like to use as the basis for further exploration.
To do so:
First set the project_id of the Workshop to be that of the desired project,
so that you may omit specifying project_id in every method call, and to provide
access to the project field.
w.set_project(project_id=project_id)
Retrieve the blueprint_id associated with the model desired to be used
as a starting point. This can be achieved in multiple ways.
If you are working with the datarobot python package, you may simply retrieve
the desired blueprint either by using the API to search a project’s menu:
menu = w.project.get_blueprints()
blueprint_id = menu[0].id
Note: If you’d like to visualize the blueprints to easily find the one you’d like to clone, here is an example of how to achieve it.
You can also search a project’s leaderboard models.
models = w.project.get_models()
blueprint_id = models[0].blueprint_id
Or by navigating to the leaderboard in the UI to obtain a specific model id via the
URL bar, which can be used to directly retrieve a model,
which will have a blueprint_id field.
Once the blueprint_id is obtained, it may be used to clone a blueprint.
bp = w.clone(blueprint_id=blueprint_id)
The source code to create the blueprint from scratch can be retrieved with a simple command.
bp.to_source_code()
Which might output:
keras = w.Tasks.KERASC(...)
keras_blueprint = w.BlueprintGraph(keras)
This is the code necessary to execute to create the exact same blueprint from scratch. This is useful as it can be modified to create a desired blueprint similar to the cloned blueprint.
If you’d like to make modifications and save in place (as opposed to making another copy),
omit the final line which creates a new BlueprintGraph, the call to (w.Blueprint),
and instead, simply call the blueprint you’d like to overwrite on the new final task:
keras = w.Tasks.KERASC(...)
# keras_blueprint = w.BlueprintGraph(...)
bp(keras).save()
The example notebook also provides a walkthrough of this flow.
Navigate to “Describe > Blueprint” and choose “Copy and Edit.”
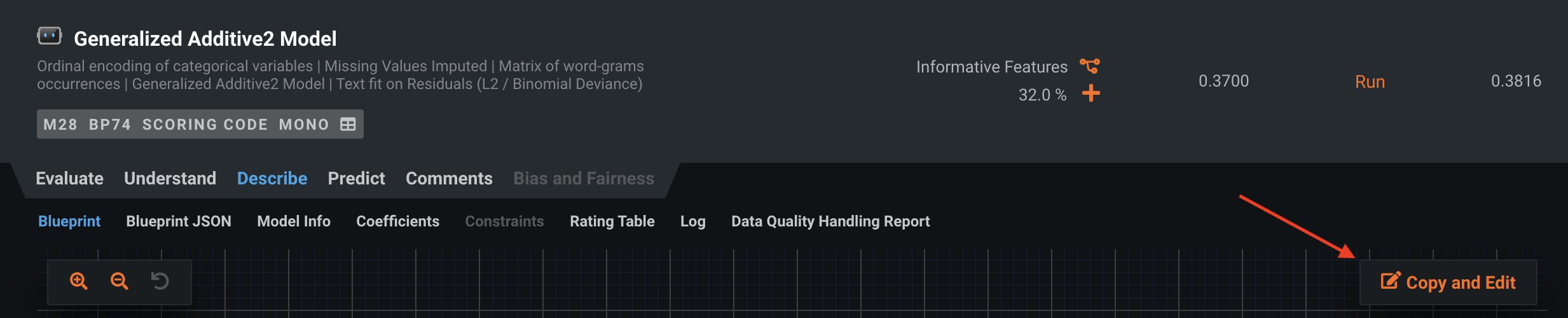
DataRobot will open the blueprint editor, where you can directly modify the blueprint, for example to incorporate new and interesting preprocessing or stack with other models. Or, you can simply save it to be used on other projects.
Validation¶
Blueprints have built-in validation and guardrails in both the UI and Blueprint Workshop in order to allow you to focus on your own goals, rather than having to worry about remembering the requirements and all the ways each task impacts the data from a specification standpoint.
This means requirements of tasks like only allowing certain data types, a certain type of sparsity, whether they can handle missing values or whether they will impute them, any requirements of column count and more will be automatically checked and any warnings or errors will be presented to you.
Furthermore other “structural” checks will be performed to ensure that the blueprint is properly connected, contains no cycles, and in general can be executed.
In the Blueprint Workshop, simply call .save() and the blueprint will be automatically
validated.
pni = w.Tasks.PNI2(w.TaskInputs.CAT)
binning = w.Tasks.BINNING(pni)
keras = w.Tasks.KERASC(binning)
invalid_keras_blueprint = w.BlueprintGraph(keras).save()
invalid_keras_blueprint.show(vertical=True)
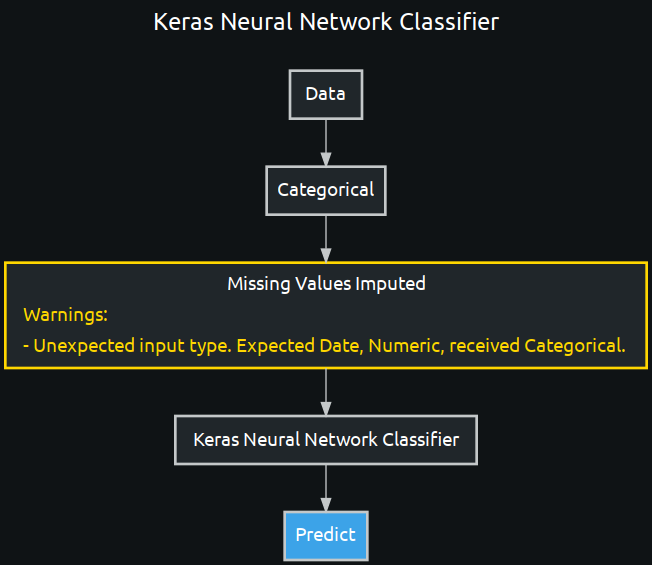
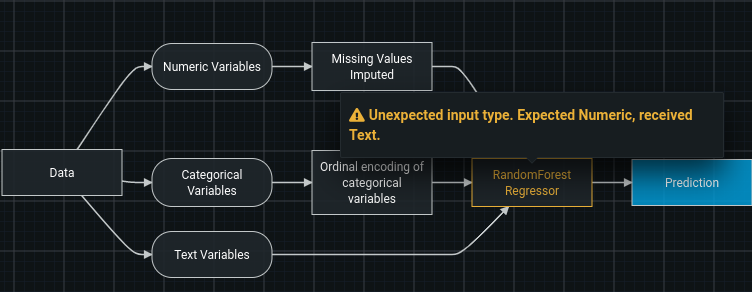
Constraints¶
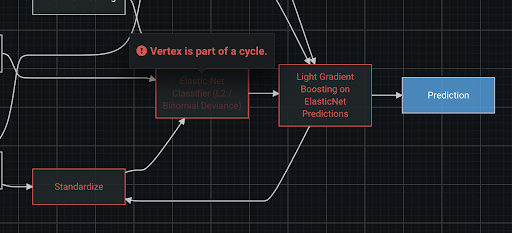
Every blueprint is required to have no cycles–the flow of data must be in one direction and never pass through the same node more than once. If a cycle is introduced, DataRobot will provide an error in the same fashion as other validation, indicating which nodes caused the issue.
Training¶
Let’s use our keras_bp from previous examples.
We can retrieve our project_id by navigating to a project in the UI and copying
it from the URL bar .../project/<project_id>/..., or by calling .id on a
DataRobot Project, if using the DR Python client.
keras_bp.train(project_id=project_id)
If the project_id is set on the Workshop, you may omit the argument to the
train method.
w.set_project(project_id=project_id) keras_bp.train()
Ensure your model is up-to-date, check for any warnings or errors, and simply press the “Train” button. Select any necessary settings.
Searching for a Blueprint¶
You may search blueprints by optionally specifying a portion of a title or description of a blueprint, and may optionally specify one or more tags which you have created and tagged blueprints with.
By default, the search results will be a python generator, and the actual blueprint data will not be requested until yielded in the generator.
You may provide the flag as_list=True in order to retrieve all of the blueprints
as a list immediately (note this will be slower, but all data will be delivered at once).
You may provide the flag show=True in order to visualize each blueprint returned which
will automatically retrieve all data (as_list=True).
shown_bps = w.search_blueprints("Linear Regression", show=True) # bp_generator = w.search_blueprints("Linear Regression") # bps = w.search_blueprints(tag=["deployed"], as_list=True)
Searching for blueprints is done through the AI Catalog, and works just like searching for a dataset.
You may filter by a specific tag, or search based on the title or description.
Sharing¶
Building a collection of blueprints for use by many individuals or an entire organization is a fantastic way to ensure maximum benefit and impact for your organization.
Sharing a blueprint with other individuals requires calling share on the blueprint,
and specifying the role to assign (“Consumer” by default, if omitted).
- The assigned role can be:
a “Consumer”, which means the user can view and train the blueprint
an “Editor”, which means the user can view, train, and edit the blueprint
an “Owner”, which means the user can view, train, edit, delete, and manage permissions, which includes revoking access from any other owners (including you)
from datarobot_bp_workshop.utils import Roles keras_bp.share(["alice@your-org.com", "bob@your-org.com"], role=Roles.CONSUMER) # keras_bp.share(["alice@your-org.com", "bob@your-org.com"], role=Roles.EDITOR) # keras_bp.share(["alice@your-org.com", "bob@your-org.com"], role=Roles.OWNER)
There are also similar methods to allow for sharing with a group or organization, which will require, respectively, a
group_idororganization_id.from datarobot_bp_workshop.utils import Roles keras_bp.share_with_group(["<group_id>"], role=Roles.CONSUMER) keras_bp.share_with_org(["<organization_id>"], role=Roles.CONSUMER)
In the UI, sharing a blueprint is just like sharing a dataset.
Navigate to the AI Catalog, search for the blueprint to be shared, and select it.
Next, click “Share” and specify (an) individual(s), group(s) or organization(s), and choose the role you would like to assign.