Walkthrough¶
The following is meant to provide a walkthrough of the most popularly used functionality in the Blueprint Workshop.
Separate examples are available for leveraging custom tasks and selecting specific columns from a project’s dataset.
[1]:
import datarobot as dr
[2]:
from datarobot_bp_workshop import Workshop, Visualize
[3]:
with open('../../../api.token', 'r') as f:
token = f.read()
dr.Client(token=token, endpoint='https://app.datarobot.com/api/v2')
Initialize¶
[4]:
w = Workshop()
Construct a Blueprint¶
[5]:
w.Task('PNI2')
[5]:
Missing Values Imputed (quick median) (PNI2)
Input Summary: (None)
Output Method: TaskOutputMethod.TRANSFORM
[6]:
w.Tasks.PNI2()
[6]:
Missing Values Imputed (quick median) (PNI2)
Input Summary: (None)
Output Method: TaskOutputMethod.TRANSFORM
[7]:
pni = w.Tasks.PNI2(w.TaskInputs.NUM)
rdt = w.Tasks.RDT5(pni)
binning = w.Tasks.BINNING(pni)
keras = w.Tasks.KERASC(rdt, binning)
keras.set_task_parameters_by_name(learning_rate=0.123)
keras_blueprint = w.BlueprintGraph(keras, name='A blueprint I made with the Python API').save()
[8]:
user_blueprint_id = keras_blueprint.user_blueprint_id

Inspecting Tasks¶
[10]:
pni
[10]:
Missing Values Imputed (quick median) (PNI2)
Input Summary: Numeric Data
Output Method: TaskOutputMethod.TRANSFORM
[11]:
rdt
[11]:
Smooth Ridit Transform (RDT5)
Input Summary: Missing Values Imputed (quick median) (PNI2)
Output Method: TaskOutputMethod.TRANSFORM
[12]:
binning
[12]:
Binning of numerical variables (BINNING)
Input Summary: Missing Values Imputed (quick median) (PNI2)
Output Method: TaskOutputMethod.TRANSFORM
[13]:
keras
[13]:
Keras Neural Network Classifier (KERASC)
Input Summary: Smooth Ridit Transform (RDT5) | Binning of numerical variables (BINNING)
Output Method: TaskOutputMethod.PREDICT
Task Parameters:
learning_rate (learning_rate) = 0.123
[14]:
keras.task_parameters.learning_rate
[14]:
0.123
[15]:
keras.task_parameters.batch_size = 32
[16]:
keras
[16]:
Keras Neural Network Classifier (KERASC)
Input Summary: Smooth Ridit Transform (RDT5) | Binning of numerical variables (BINNING)
Output Method: TaskOutputMethod.PREDICT
Task Parameters:
batch_size (batch_size) = 32
learning_rate (learning_rate) = 0.123
[17]:
keras_blueprint
[17]:
Name: 'A blueprint I made with the Python API'
Input Data: Numeric
Tasks: Missing Values Imputed (quick median) | Smooth Ridit Transform | Binning of numerical variables | Keras Neural Network Classifier
Validation¶
We intentionally feed the wrong input data type
[18]:
pni = w.Tasks.PNI2(w.TaskInputs.CAT)
rdt = w.Tasks.RDT5(pni)
binning = w.Tasks.BINNING(pni)
keras = w.Tasks.KERASC(rdt, binning)
keras.set_task_parameters_by_name(learning_rate=0.123)
invalid_keras_blueprint = w.BlueprintGraph(keras)
[19]:
invalid_keras_blueprint.save('A blueprint with warnings (PythonAPI)', user_blueprint_id=user_blueprint_id).show()

[20]:
binning.set_task_parameters_by_name(max_bins=-22)
[20]:
Binning of numerical variables (BINNING)
Input Summary: Missing Values Imputed (quick median) (PNI2)
Output Method: TaskOutputMethod.TRANSFORM
Task Parameters:
max_bins (b) = -22
[21]:
invalid_keras_blueprint.save('A blueprint with warnings (PythonAPI)', user_blueprint_id=user_blueprint_id).show()
Binning of numerical variables (BINNING)
Invalid value(s) supplied
max_bins (b) = -22
- Must be a 'intgrid' parameter defined by: [2, 500]
Failed to save: parameter validation failed.

[22]:
keras.validate_task_parameters()
Keras Neural Network Classifier (KERASC)
All parameters valid!
[22]:
Update to the Original Valid Blueprint¶
[23]:
pni = w.Tasks.PNI2(w.TaskInputs.NUM)
rdt = w.Tasks.RDT5(pni)
binning = w.Tasks.BINNING(pni)
keras = w.Tasks.KERASC(rdt, binning)
keras.set_task_parameters_by_name(learning_rate=0.123)
keras_blueprint = w.BlueprintGraph(keras)
blueprint_graph = keras_blueprint.save('A blueprint I made with the Python API', user_blueprint_id=user_blueprint_id)
Help with Tasks¶
[24]:
help(w.Tasks.PNI2)
Help on PNI2 in module datarobot_bp_workshop.factories object:
class PNI2(datarobot_bp_workshop.friendly_repr.FriendlyRepr)
| Missing Values Imputed (quick median)
|
| Impute missing values on numeric variables with their median and create indicator variables to mark imputed records
|
| Parameters
| ----------
| output_method: string, one of (TaskOutputMethod.TRANSFORM).
| task_parameters: dict, which may contain:
|
| scale_small (s): select, (Default=0)
| Possible Values: [False, True]
|
| threshold (t): int, (Default=10)
| Possible Values: [1, 99999]
|
| Method resolution order:
| PNI2
| datarobot_bp_workshop.friendly_repr.FriendlyRepr
| builtins.object
|
| Methods defined here:
|
| __call__(zelf, *inputs, output_method=None, task_parameters=None, output_method_parameters=None, x_transformations=None, y_transformations=None, freeze=False, version=None)
|
| __friendly_repr__(zelf)
|
| documentation(zelf, auto_open=False)
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| description = 'Impute missing values on numeric variables with ...eate...
|
| label = 'Missing Values Imputed (quick median)'
|
| task_code = 'PNI2'
|
| task_parameters = scale_small (s): select, (Default=0)
|
| threshold (t):...
|
| ----------------------------------------------------------------------
| Methods inherited from datarobot_bp_workshop.friendly_repr.FriendlyRepr:
|
| __repr__(self)
| Return repr(self).
|
| ----------------------------------------------------------------------
| Data descriptors inherited from datarobot_bp_workshop.friendly_repr.FriendlyRepr:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
List Task Categories¶
[25]:
w.list_categories(show_tasks=False)
Custom
Preprocessing
Numeric Preprocessing
Data Quality
Dimensionality Reducer
Scaling
Categorical Preprocessing
Text Preprocessing
Image Preprocessing
Summarized Categorical Preprocessing
Geospatial Preprocessing
Models
Regression
Binary Classification
Multi-class Classification
Boosting
Unsupervised
Anomaly Detection
Clustering
Calibration
Other
Column Selection
Automatic Feature Selection
[25]:
Search for Tasks by Name¶
[26]:
w.search_tasks('keras')
[26]:
Keras Autoencoder with Calibration: [KERAS_AUTOENCODER_CAL]
- Keras Autoencoder for Anomaly Detection with Calibration
Keras Autoencoder: [KERAS_AUTOENCODER]
- Keras Autoencoder for Anomaly Detection
Keras Neural Network Classifier: [KERASC]
- Keras Neural Network Classifier
Keras Neural Network Classifier: [KERASMULTIC]
- Keras Neural Network Multi-Class Classifier
Keras Neural Network Regressor: [KERASR]
- Keras Neural Network Regressor
Keras Variational Autoencoder with Calibration: [KERAS_VARIATIONAL_AUTOENCODER_CAL]
- Keras Variational Autoencoder for Anomaly Detection with Calibration
Keras Variational Autoencoder: [KERAS_VARIATIONAL_AUTOENCODER]
- Keras Variational Autoencoder for Anomaly Detection
Keras encoding of text variables: [KERAS_TOKENIZER]
- Text encoding based on Keras Tokenizer class
Regularized Quantile Regressor with Keras: [KERAS_REGULARIZED_QUANTILE_REG]
- Regularized Quantile Regression implemented in Keras
Search Custom Tasks¶
[27]:
w.search_tasks('Awesome')
[27]:
Awesome Model: [CUSTOMR_6019ae978cc598a46199cee1]
- This is the best model ever.
Flexible Search¶
[28]:
w.search_tasks('bins')
[28]:
Binning of numerical variables: [BINNING]
- Bin numerical values into non-uniform bins using decision trees
Elastic-Net Regressor (L1 / Least-Squares Loss) with Binned numeric features: [BENETCD2]
- Bin numerical values into non-uniform bins using decision trees, followed by Elasticnet model using block coordinate descent-- a common form of derivated-free optimization. Based on lightning CDRegressor.
[29]:
w.search_tasks('Preproc')
[29]:
Bind branches: [BIND]
- Bind data processing workflows within a type of data. e.g. bind 2 kinds of numeric preprocessing or 2 kinds of text preprocessing
Binning of numerical variables: [BINNING]
- Bin numerical values into non-uniform bins using decision trees
Buhlmann credibility estimates for high cardinality features: [CRED1]
- Buhlmann Credibility Estimates from categorical features with high cardinality. This transformer calculates credibility estimates using a proprietary, DataRobot-developed methodology
Categorical Embedding: [CATEMB]
- Dense embedding of categorical features. Transform categorical features into a dense vector of a fixed size
Category Count: [PCCAT]
- Create a count matrix from categorical features
Constant Splines: [GS]
- Convert numeric features into piece-wise constant spline base expansion. Missing values are inputed with the median prior to creating splines
Fasttext Word Vectorization and Mean text embedding: [TXTEM1]
- Convert raw text fields into a vector. Based on fasttext and word2vec.
Geospatial Location Converter: [GEO_IN]
- Convert Geospatial Location features.
Grayscale Downscaled Image Featurizer: [IMG_GRAYSCALE_DOWNSCALED_IMAGE_FEATURIZER]
- Image featurization by converting to grayscale, downscaling the image, and flattening the image into a one-dimensional array of pixels
Keras encoding of text variables: [KERAS_TOKENIZER]
- Text encoding based on Keras Tokenizer class
Log Transformer: [LOGT]
- Log transform preprocessor.
Matrix of word-grams occurrences: [PTM3]
- Convert raw text fields into a document-term matrix. Based on scikit-learn TfidfVectorizer.
Missing Values Imputed (arbitrary or quick median): [PNIA4]
- Impute missing values on numeric variables with arbitrary number
Missing Values Imputed (quick median): [PNI2]
- Impute missing values on numeric variables with their median and create indicator variables to mark imputed records
NLTK Sentiment Featurizer: [NLTK_SENTIMENT]
- Computes NLTK Sentiment for text features
No Post Processing: [IMAGE_POST_PROCESSOR]
- Post Processing of Pretrained Convolutional Neural Network Image features
Normalizer: [NORM]
- Normalize features by scaling samples individually to unit norm. Based on scikit-learn Normalize
Numeric Data Cleansing: [NDC]
- Impute missing/disguised missing values on numeric variables with their median and create indicator variables to mark records with data quality issues
One-Hot Encoding: [PDM3]
- One-Hot (or dummy-variable) transformation of categorical features
OpenCV Detect Largest Rectangle: [OPENCV_DETECT_LARGEST_RECTANGLE]
- Detects largest rectangle from images
OpenCV Image Featurizer: [OPENCV_FEATURIZER]
- Computes OpenCV features for images
Ordinal encoding of categorical variables: [ORDCAT2]
- Ordinal transformation of categorical features. Recodes categorical features as integers based on either the lexicographic ordering of the categorical values, the frequency of the categorical values, the response or randomly
Pretrained Multi-Level Global Average Pooling Image Featurizer: [IMGFEA]
- Image featurization using pre-trained deep neural network models.
Pretrained TinyBERT Featurizer: [TINYBERTFEA]
- Convert raw text fields into a vector. Based on Tiny-Bert embeddings.
Search for differences: [DIFF3]
- Greedy Search for differences between pairs of features, using a proprietary DataRobot-developed methodology
Search for ratios: [RATIO3]
- Greedy Search for ratios. Adds pairs of ratios to a linear model until the model stops improving. Then adds those ratios to the main dataset.
Single Column Converter for Summarized Categorical: [SCBAGOFCAT2]
- Selects a single Summarized Categorical column by name
SpaCy Named Entity Recognition Detector: [SPACY_NAMED_ENTITY_RECOGNITION]
- Computes Named Entity Recognition for text features
Sparse Interaction Machine: [SPOLY]
- Sparse to Sparse transform for polynomial interactions
Spatial Neighborhood Featurizer: [GEO_NEIGHBOR_V1]
- Spatial Neighborhood Featurizer
Summarized Categorical to Sparse Matrix: [CDICT2SP]
- Convert the count dict data into the sparse matrix
TextBlob Sentiment Featurizer: [TEXTBLOB_SENTIMENT]
- Computes TextBlob Sentiment for text features
Univariate credibility estimates with L2: [CRED1b1]
- L2 Regularization Credibility Estimator
[30]:
[a.task_code for a in w.search_tasks('decision')]
[30]:
['BINNING', 'BENETCD2', 'RFC', 'RFR']
[31]:
w.Tasks.RFC
[31]:
ExtraTrees Classifier (Gini): [RFC]
- Random Forests based on scikit-learn. Random forests are an ensemble method where hundreds (or thousands) of individual decision trees are fit to boostrap re-samples of the original dataset. ExtraTrees are a variant of RandomForests with even more randomness.
Quick Description¶
[32]:
w.Tasks.PDM3.description
[32]:
'One-Hot (or dummy-variable) transformation of categorical features'
View Documentation For a Task¶
[33]:
binning.documentation()
[33]:
'https://app.datarobot.com/model-docs/tasks/BINNING-Binning-of-numerical-variables.html'
View Task Parameter Values¶
As an example, let’s look at the Binning Task
[34]:
binning.get_task_parameter_by_name('max_bins')
[34]:
20
Modify A Task Parameter¶
[35]:
binning.set_task_parameters_by_name(max_bins=22)
[35]:
Binning of numerical variables (BINNING)
Input Summary: Missing Values Imputed (quick median) (PNI2)
Output Method: TaskOutputMethod.TRANSFORM
Task Parameters:
max_bins (b) = 22
Or set with the key / short-name directly¶
[36]:
binning.task_parameters.b = 22
Validate Parameters¶
[37]:
binning.task_parameters.b = -22
[38]:
binning.validate_task_parameters()
Binning of numerical variables (BINNING)
Invalid value(s) supplied
max_bins (b) = -22
- Must be a 'intgrid' parameter defined by: [2, 500]
[38]:
[39]:
binning.set_task_parameters(b=22)
[39]:
Binning of numerical variables (BINNING)
Input Summary: Missing Values Imputed (quick median) (PNI2)
Output Method: TaskOutputMethod.TRANSFORM
Task Parameters:
max_bins (b) = 22
Make sure it’s valid…¶
[40]:
binning.validate_task_parameters()
Binning of numerical variables (BINNING)
All parameters valid!
[40]:
Update an existing blueprint in personal repository by passing the user_blueprint_id¶
[41]:
blueprint_graph = keras_blueprint.save('A blueprint I made with the Python API (updated)', user_blueprint_id=user_blueprint_id)
[42]:
assert user_blueprint_id == blueprint_graph.user_blueprint_id


Delete a Blueprint From Your Personal Repository¶
[45]:
w.delete(user_blueprint_id)
Blueprints deleted.
Existing Blueprints API to Retrieve Leaderboard Blueprints¶
[46]:
project_id = '5eb9656901f6bb026828f14e'
project = dr.Project.get(project_id)
menu = project.get_blueprints()
[47]:
for bp in menu[6:9]:
Visualize.show_dr_blueprint(bp)

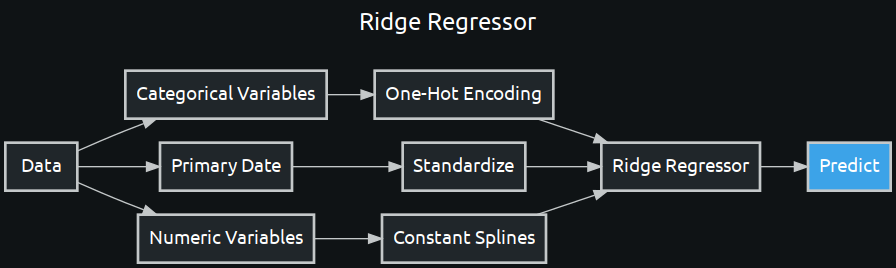

Clone a Blueprint From a Leaderboard¶
[48]:
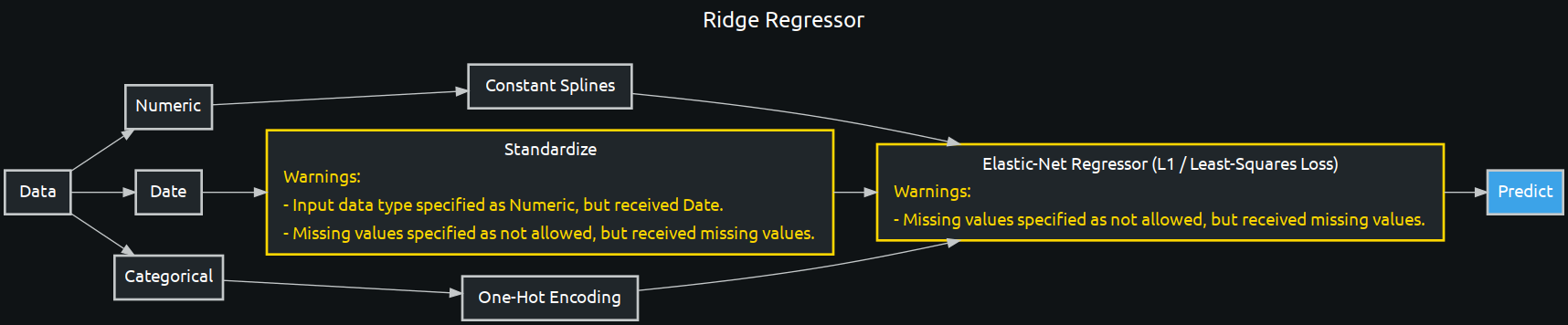
ridge = menu[7]
blueprint_graph = w.clone(blueprint_id=ridge.id, project_id=project_id)
blueprint_graph.show()
[49]:
ridge.id, project_id
[49]:
('1774086bd8bfd4e1f45c5ff503a99ee2', '5eb9656901f6bb026828f14e')
Any Blueprint Can Be Used as a Tutorial¶
[50]:
source_code = blueprint_graph.to_source_code(to_stdout=True)
w = Workshop(user_blueprint_id='61d5db87e0f01fe2a6ce3335')
rst = w.Tasks.RST(w.TaskInputs.DATE)
pdm3 = w.Tasks.PDM3(w.TaskInputs.CAT)
pdm3.set_task_parameters(cm=500, sc=25)
gs = w.Tasks.GS(w.TaskInputs.NUM)
enetcd = w.Tasks.ENETCD(rst, pdm3, gs)
enetcd.set_task_parameters(a=0)
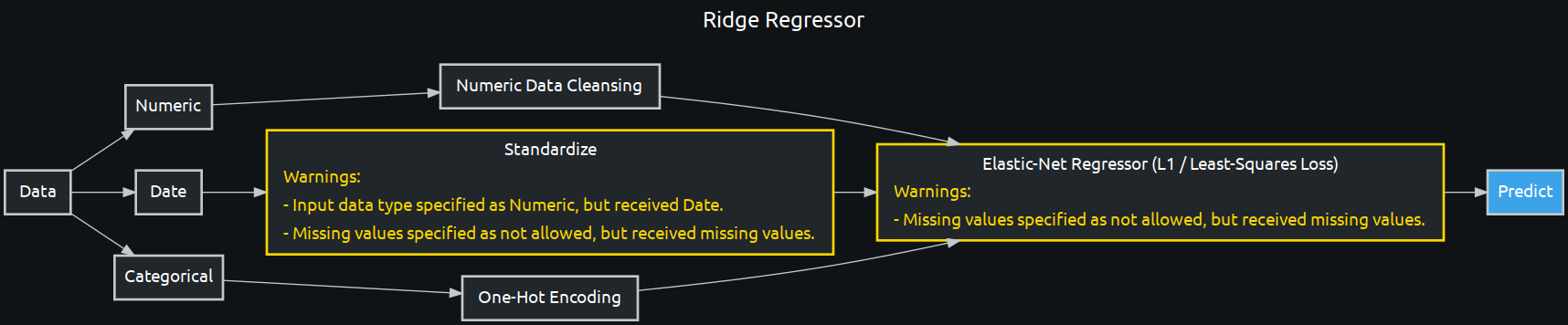
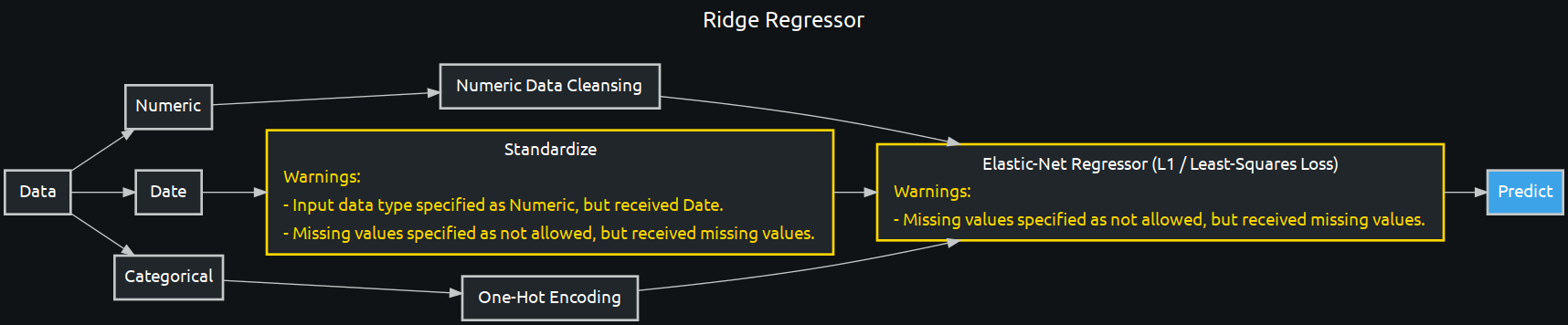
enetcd_blueprint = w.BlueprintGraph(enetcd, name='Ridge Regressor')
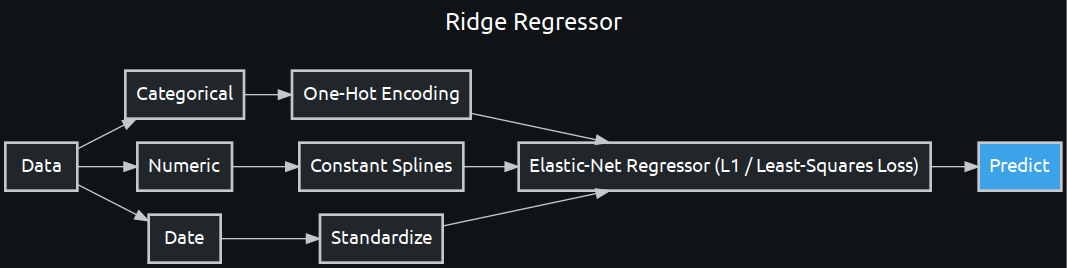
Modify the source code¶
[54]:
#w = Workshop()
rst = w.Tasks.RST(w.TaskInputs.DATE)
# Use numeric data cleansing instead
ndc = w.Tasks.NDC(w.TaskInputs.NUM)
pdm3 = w.Tasks.PDM3(w.TaskInputs.CAT)
pdm3.set_task_parameters(cm=500, sc=25)
enetcd = w.Tasks.ENETCD(rst, ndc, pdm3)
enetcd.set_task_parameters(a=0.0)
enetcd_blueprint = w.BlueprintGraph(enetcd, name='Ridge Regressor')
[55]:
enetcd_blueprint.show()
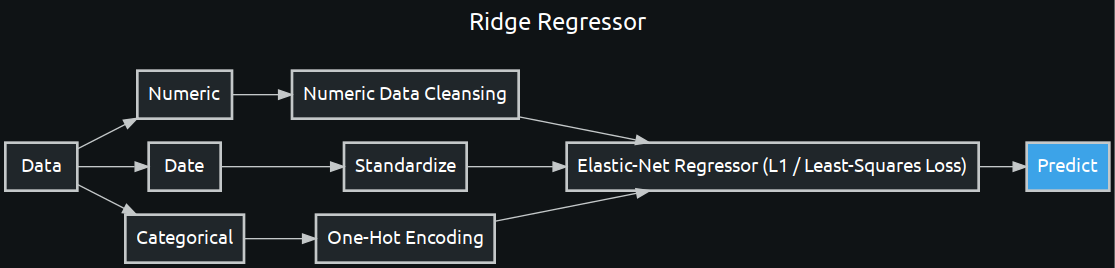
Add the Blueprint to a Project and Train It¶
[56]:
project_id = '5eb9656901f6bb026828f14e'
[57]:
enetcd_blueprint.save()
[57]:
Name: 'Ridge Regressor'
Input Data: Date | Categorical | Numeric
Tasks: Standardize | One-Hot Encoding | Numeric Data Cleansing | Elastic-Net Regressor (L1 / Least-Squares Loss)
[58]:
enetcd_blueprint.train(project_id=project_id)
Training requested! Blueprint Id: fa329535f1e5f5465e2c55024aacb910
[58]:
Name: 'Ridge Regressor'
Input Data: Date | Categorical | Numeric
Tasks: Standardize | One-Hot Encoding | Numeric Data Cleansing | Elastic-Net Regressor (L1 / Least-Squares Loss)
[59]:
enetcd_blueprint.delete()
Blueprint deleted.